Bringing CLIP to the Italian language with Jax and Hugging Face
 CLIP is a model published by OpenAI that is able to
learn visual concepts by natural language supervision. It does this by embedding images and their corresponding caption
into a joint space and contrastively minimizing their distance. OpenAI only published weights for CLIP trained on
english data. That's why during the JAX/Flax community event organized by Hugging Face and Google, we from
the clip-italian team wanted to try to train a CLIP
version that understands 🤌Italian🤌.
CLIP is a model published by OpenAI that is able to
learn visual concepts by natural language supervision. It does this by embedding images and their corresponding caption
into a joint space and contrastively minimizing their distance. OpenAI only published weights for CLIP trained on
english data. That's why during the JAX/Flax community event organized by Hugging Face and Google, we from
the clip-italian team wanted to try to train a CLIP
version that understands 🤌Italian🤌.
The Data
The original CLIP model used 400 Million image/caption pairs and took two weeks to train on 256 GPUs. For a team like ours, with a combined budget of zero dollars both this amount of data and the compute would normally be completely out of reach. Thanks to Google and Hugging Face we were given the chance to train our version of CLIP on a TPU v3-8, which only left us with the challenge to gather enough image/text pairs to feed the model.
For reference: The largest public Italian image/caption dataset that we were aware of before the competition is MSCOCO-it. It contains roughly 83.000 images in its training set and is basically a machine translated version of the popular MSCOCO dataset. This is a rather modest number of images, and the quality of the captions is highly dependent on the translation.
During the competition we found out about the WIT dataset which in simple terms is just a list of all images from Wikipedia with their respective captions. It contains a whopping 37 million image/text pairs. Unfortunately though most of them are not in Italian but one of the 107 other languages represented in Wikipedia. Furthermore, many of its captions consist of ontological knowledge and encyclopedic facts. Therefore, we tried to filter out the useful captions by removing ones that consisted mainly of proper nouns. This left us with around 500k image/caption pairs that seemed mostly useful to us.
Next we thought about replicating the translation effort done for the MSCOCO-it and the Conceptual Captions dataset immediately came to mind. It's an english image/caption datset consisting of 3.3 million pairs. Translating it could give a huge performance boost to our model. All our money was already spent on Google and Hugging Face swag so our free DeepL test accounts were all we could invest. Together we managed to translate over 700k of the captions. We assessed the quality of 100 of those translations in detail and were very happy with almost all of them.
These efforts left us with close to 1.4 million captioned images. Initially we were a bit hesitant about the quality of the translated captions and the usefulness of the rather encyclopedic captions from Wikipedia so for good measure we spiced up our resulting dataset stew with some 30k native italian captions from the "image of the day" section of ILPOST, a famous italian newspaper.
After realizing that this was all the data we could gather with the given time and resources we knew that we had to round off our data strategy with a lot of augmentations to even get close to a useful model. We were not able to find good text augmentations, so we settled with leaving the text unchanged. For the images however we chose very heavy augmentations that included affine and projective transforms as well as occasional equalization and random changes to brightness, contrast, saturation and hue. We made sure to keep hue augmentations limited however, to still give the model the ability to learn color definitions.
The Training
We used a hybrid form of CLIP for our training. It uses CLIPs pretrained ViT-B/32 as a vision encoder and a version of BERT that was pretrained on Italian texts. After some tests we found out that we could make the best of the pretrained models by initially keeping both of them frozen and only unfreezing the backbones once the reprojection layers had converged.
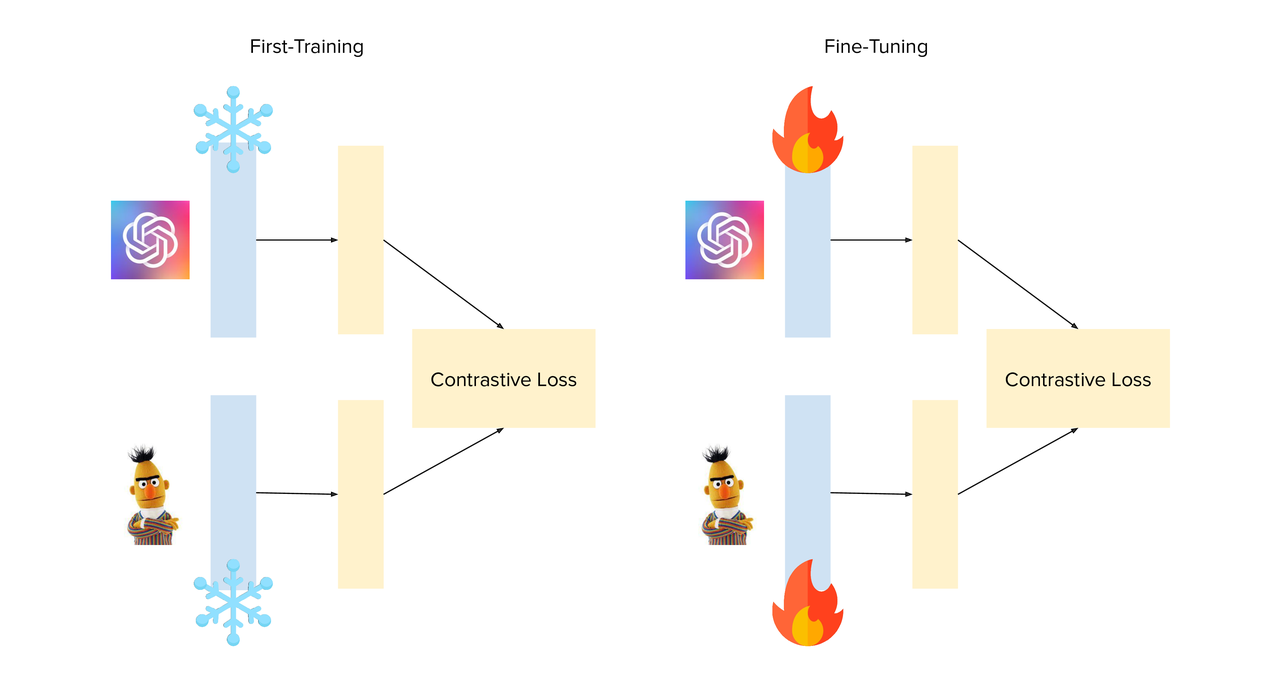
Another thing that we found out after some testing was that AdamW was not suitable for fine-tuning this model. Our hypothesis was that the weight decay would mess with the original weights that were already trained on huge amounts of data. So instead we moved to Adabelief with adaptive gradient clipping and cosine annealing as this is a combination that had worked for us in other projects. Since we were using JAX and Optax creating and using this optimizer was done in few lines of code:
optimizer = optax.chain( optax.adaptive_grad_clip(0.01, eps=0.001), optax.scale_by_belief(), optax.scale_by_schedule(decay_lr_schedule_fn), optax.scale(-1.0), )
One last trick that we learned from Nils Reimers video was to try and fix the logit_scale parameter at 20 which seemed to work well in our case. Together with the other changes to the default training code this helped us to reduce the training loss significantly and ultimately led to a better performance of our model.
Most of us had little to no previous experience with JAX but its similarity to numpy and the training code provided by Hugging Face made that a non-issue. Understanding and modifying the code was super simple and experimenting with JAX and the provided TPU-VM felt fast and allowed us to keep turnaround times surprisingly low.
The Results
At the time of the competition there were no other italian CLIP models available so to get a baseline for our model we used mClip, a multilingual version of CLIP that was generated using the original CLIP model and Multilingal Knowledge Distillation. We wrote scripts to compare our model against mClip in two tasks:
The image retrieval benchmark was computed on the validation set of MSCOCO-it that was not used during training. Given an input caption from the dataset, we compute the rank of the corresponding image. As evaluation metrics we use the MRR@K (higher is better).
| MRR | CLIP-Italian | mCLIP |
|---|---|---|
| MRR@1 | 0.3797 | 0.2874 |
| MRR@5 | 0.5039 | 0.3957 |
| MRR@10 | 0.5204 | 0.4129 |
The Zero-shot image classification experiment replicates an evaluation done by OpenAI. In order to run it we used DeepL to translate the image labels in ImageNet and rank similarity of the embedded validation-set images compared to their description embedding. We didn't do any manual engineering of the labels or prompt and evaluated the accuracy at different levels.
| Accuracy | CLIP-Italian | mCLIP |
|---|---|---|
| Accuracy@1 | 22.11 | 20.15 |
| Accuracy@5 | 43.69 | 36.57 |
| Accuracy@10 | 52.55 | 42.91 |
| Accuracy@100 | 81.08 | 67.11 |
But why show numbers when we can show images?
When using our model to search through ~150.000 of the unused images from the Conceptual Captions dataset we can see that the model understands many visual concepts in natural language:

The Extras
One cool feature that to the best of our knowledge is actually a novel contribution, is an algorithm to generate a heatmap for a textual concept in an image.
We can do this by masking different areas in an image and checking which of them generate the closest embedding to the embedding of a text query.
This allows us to identify the areas in an image that are most relevant for the given query.
With this simple method we can show some of the models remarkable capabilities. The example below shows us where in the image the model sees "a shark" and where it sees "a horse":

To us these capabilities were very unexpected since the model was never trained with this task in mind.
It shows however that a large amount of data can teach a model to recognize common features across object classes even in a zero shot setting.
If you want to have a look at the code used for this localization feature you can play with this colab notebook.
The Code
For a live demo of all the features, have a look at our HuggingFace Space.
For the full code we used during the project you can have a look at our GitHub.
We tried to publish as much code as possible to make our findings available to everyone. If you use any of it please cite our paper:
@misc{bianchi2021contrastive,
title={Contrastive Language-Image Pre-training for the Italian Language},
author={Federico Bianchi and Giuseppe Attanasio and Raphael Pisoni and
Silvia Terragni and Gabriele Sarti and Sri Lakshmi},
year={2021},
eprint={2108.08688},
archivePrefix={arXiv},
primaryClass={cs.CL}
}