Sharpened Cosine Distance as an Alternative for Convolutions
Some days ago Brandon Rohrer retweeted his own twitter thread from 2020 in which he makes the argument that convolutions are
actually pretty bad at extracting features. In it he proposes a method to improve feature extraction that seemed compelling to me.
The formula for this Sharpened Cosine Distance is the following:
$$ scd(s, k) = sign(s \cdot k)\Biggl(\frac{s \cdot k}{(\Vert{s}\Vert+q)(\Vert{k}\Vert+q)}\Biggr)^p $$
I decided to try this idea out and created a neural network layer based on this formula and as it turns out it actually works!
If you want to know more about the details of why convolution is such a bad feature extractor I suggest you check out the full thread of the tweet below.
I promis it's worth it!
The thing that has surprised me the most about convolution is that it’s used in neural networks as a feature detector, but it’s pretty bad at detecting features.
— Brandon Rohrer (@_brohrer_) February 24, 2020
Long story short: As you can see below if you convolve a kernel over a sequence it does not give the highest activation for a signal that matches the kernel:
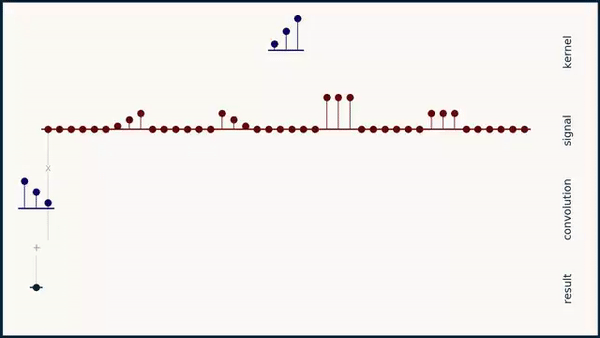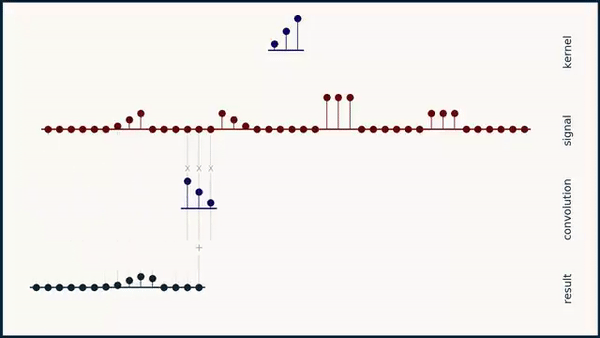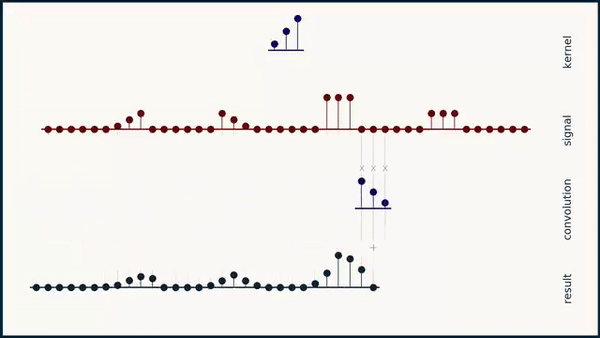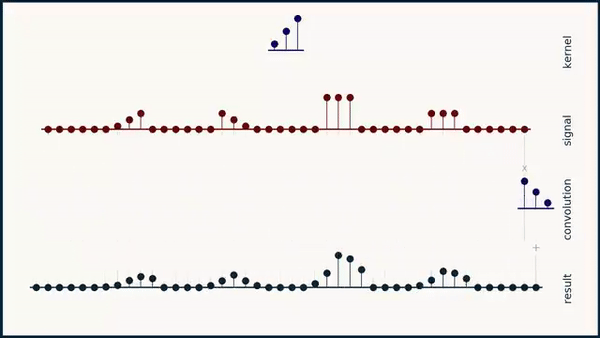
If you apply the formula for the Sharpened Cosine Distance however the result looks more the way we want it to look. A feature is detected independent of its sign or scale as long as the scale is significantly larger than \( p \).
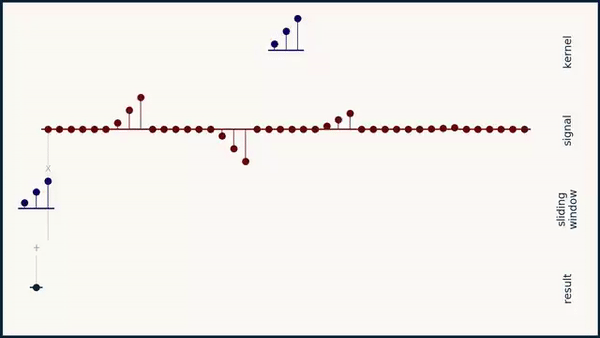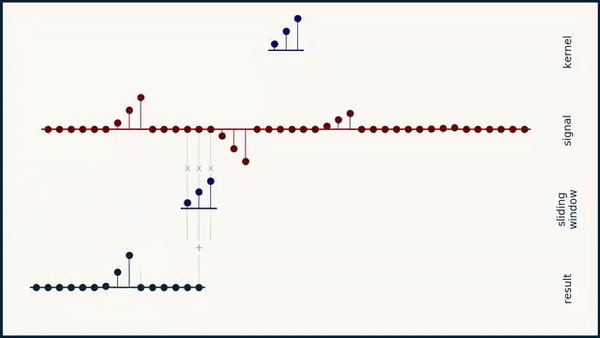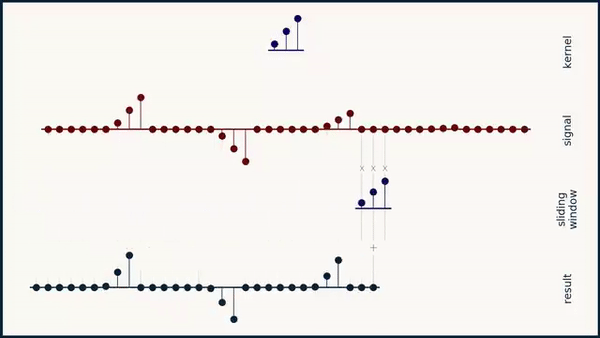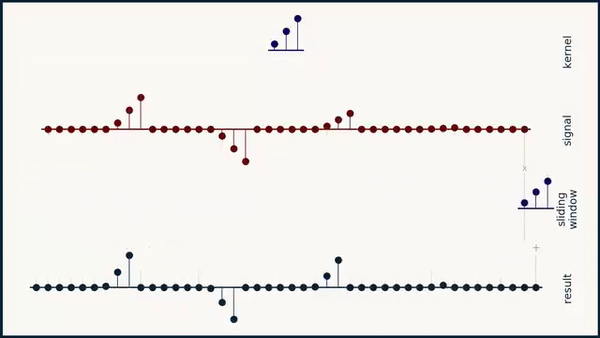
The implementations is a bit more involved than the formula since we need to reimplement the sliding window mechanism that is traditionally contained in the convolution code. Furthermore, we need to make sure the gradients stay stable so e.g. we need to avoid \( p\) and \( q\) getting negative which I do by squaring them.
So where is the full implementation of this Sharpened Cosine Distance Layer? Find the Keras Code below or have a look at the gist:
import tensorflow as tf class CosSimConv2D(tf.keras.layers.Layer): def __init__(self, units=32): super(CosSimConv2D, self).__init__() self.units = units self.kernel_size = 3 def build(self, input_shape): self.in_shape = input_shape self.flat_size = self.in_shape[1] * self.in_shape[2] self.channels = self.in_shape[3] self.w = self.add_weight( shape=(1, self.channels * tf.square(self.kernel_size), self.units), initializer="glorot_uniform", trainable=True, ) self.p = self.add_weight( shape=(self.units,), initializer='zeros', trainable=True) self.q = self.add_weight( shape=(1,), initializer='zeros', trainable=True) def l2_normal(self, x, axis=None, epsilon=1e-12): square_sum = tf.reduce_sum(tf.square(x), axis, keepdims=True) x_inv_norm = tf.sqrt(tf.maximum(square_sum, epsilon)) return x_inv_norm def stack3x3(self, image): stack = tf.stack( [ tf.pad(image[:, :-1, :-1, :], tf.constant([[0,0], [1,0], [1,0], [0,0]])), # top row tf.pad(image[:, :-1, :, :], tf.constant([[0,0], [1,0], [0,0], [0,0]])), tf.pad(image[:, :-1, 1:, :], tf.constant([[0,0], [1,0], [0,1], [0,0]])), tf.pad(image[:, :, :-1, :], tf.constant([[0,0], [0,0], [1,0], [0,0]])), # middle row image, tf.pad(image[:, :, 1:, :], tf.constant([[0,0], [0,0], [0,1], [0,0]])), tf.pad(image[:, 1:, :-1, :], tf.constant([[0,0], [0,1], [1,0], [0,0]])), # bottom row tf.pad(image[:, 1:, :, :], tf.constant([[0,0], [0,1], [0,0], [0,0]])), tf.pad(image[:, 1:, 1:, :], tf.constant([[0,0], [0,1], [0,1], [0,0]])) ], axis=3) return stack def call(self, inputs, training=None): x = self.stack3x3(inputs) x = tf.reshape(x, (-1, self.flat_size, self.channels * tf.square(self.kernel_size))) q = tf.square(self.q) / 10 x_norm = self.l2_normal(x, axis=2) + q w_norm = self.l2_normal(self.w, axis=1) + q sign = tf.sign(tf.matmul(x, self.w)) x = tf.matmul(x / x_norm, self.w / w_norm) x = tf.abs(x) + 1e-12 x = tf.pow(x, tf.nn.softmax(self.p)) x = sign * x x = tf.reshape(x, (-1, self.in_shape[1], self.in_shape[2], self.units)) return x