My First Paper
In December of 2017 after completing the statistical evaluations for a paper published by Kristina Eichbichler from the Medical University of Vienna I was looking for a new freetime project. As luck would have it at the same time I got in contact with Professor Tammam Tillo who happened to be the new Computer Vision specialist at my University. He suggested me to work on depth estimation.  I had of course experimented with a couple of vision tasks like simple classification of MNIST digits or simple semantic segmentation but had never gotten to a point where I was very excited about the results. This however struck me as an interesting and exciting project. I read over some papers describing the topic and finally decided to try and implement Michele Mancinis J-MOD2: Joint Monocular Obstacle Detection and Depth Estimation. What struck me most about it was that they used a virtual environment (AirSim) to get hold of a large amount of simulated scenes and their corresponding dense depth maps from a semi-realistic environment. When I told my professor about my ideas he suggested using this project as a thesis project and offered himself as a thesis advisor. He also suggested we extend the architecture to support stereo vision to compare the performance of these two approaches. I experimented with a couple of standard approaches essentially consisting of trying out a few classical network architectures as an encoder backbone for my crude decoder. Since my main constraint was the VRAM in my GTX1080 I soon decided to cut out the obstacle-detector branch of my network and instead focus on improving the main architecture of the network that was already performing quite decently.
I had of course experimented with a couple of vision tasks like simple classification of MNIST digits or simple semantic segmentation but had never gotten to a point where I was very excited about the results. This however struck me as an interesting and exciting project. I read over some papers describing the topic and finally decided to try and implement Michele Mancinis J-MOD2: Joint Monocular Obstacle Detection and Depth Estimation. What struck me most about it was that they used a virtual environment (AirSim) to get hold of a large amount of simulated scenes and their corresponding dense depth maps from a semi-realistic environment. When I told my professor about my ideas he suggested using this project as a thesis project and offered himself as a thesis advisor. He also suggested we extend the architecture to support stereo vision to compare the performance of these two approaches. I experimented with a couple of standard approaches essentially consisting of trying out a few classical network architectures as an encoder backbone for my crude decoder. Since my main constraint was the VRAM in my GTX1080 I soon decided to cut out the obstacle-detector branch of my network and instead focus on improving the main architecture of the network that was already performing quite decently.
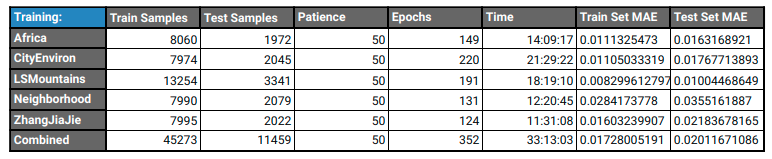
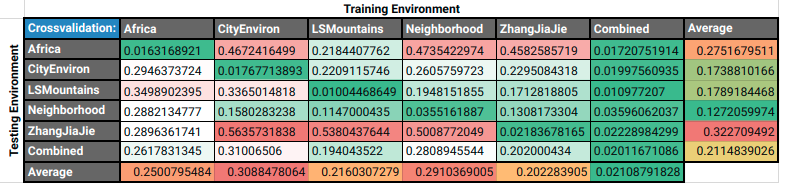
After being really happy with my architecture and the results I was able to achieve on my dataset of roughly 55,000 images collected across 6 diverse environments in AirSim I performed some cross validation to see if the model was able to generalize between environments. This showed unsurprisingly that the model was good at judging things it had already seen. Some environments were easier or harder to deal with for many models but the overall performance was of course dominated by the model trained on the whole dataset (duh!).
At that time I already preferred Xception as my model backend, so when I read about XceptionV2 being released by Google as part of their DeeplabV3 architecture for semantic segmentation (of course I try to read every Google paper!!!) I didnt think twice about implementing it for my own purpose. I also really liked the concept of atrous convolution that I had not heard about before but made a lot of sense to me for making the model get a more global context. Finally I also implemented the skip connection from encoder to decoder inspired by U-Net and added the residual decoder modules to the architecture that had already helped me to get sharper results in previouse experiments and voilà.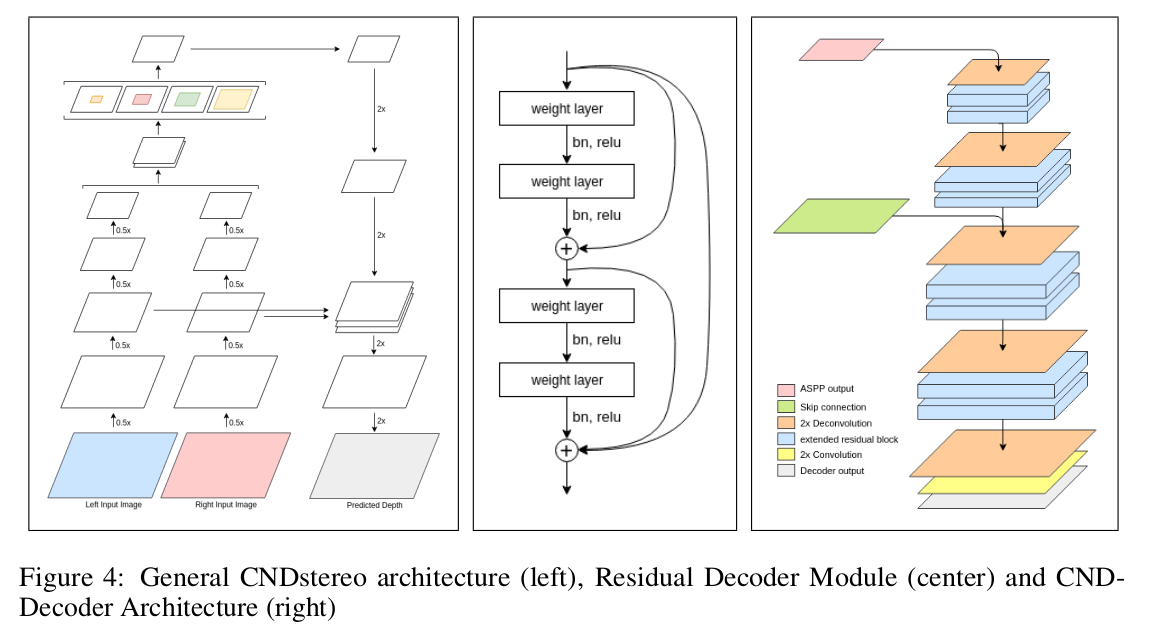
Around that same time Baidu released a large dataset of dense depth maps named ApolloScape. I mistakenly assumed that this would get the new standard dataset in depth estimation, finally replacing KITTI, so i focused all my testing on it. With my greatly improved model i was able to achieve incredible results (at the time) in both stereo and monocular configuration, visually outperforming all competitors on other datasets, however I have yet to see results published on ApolloScape from someone else working on depth estimation...
Mono results: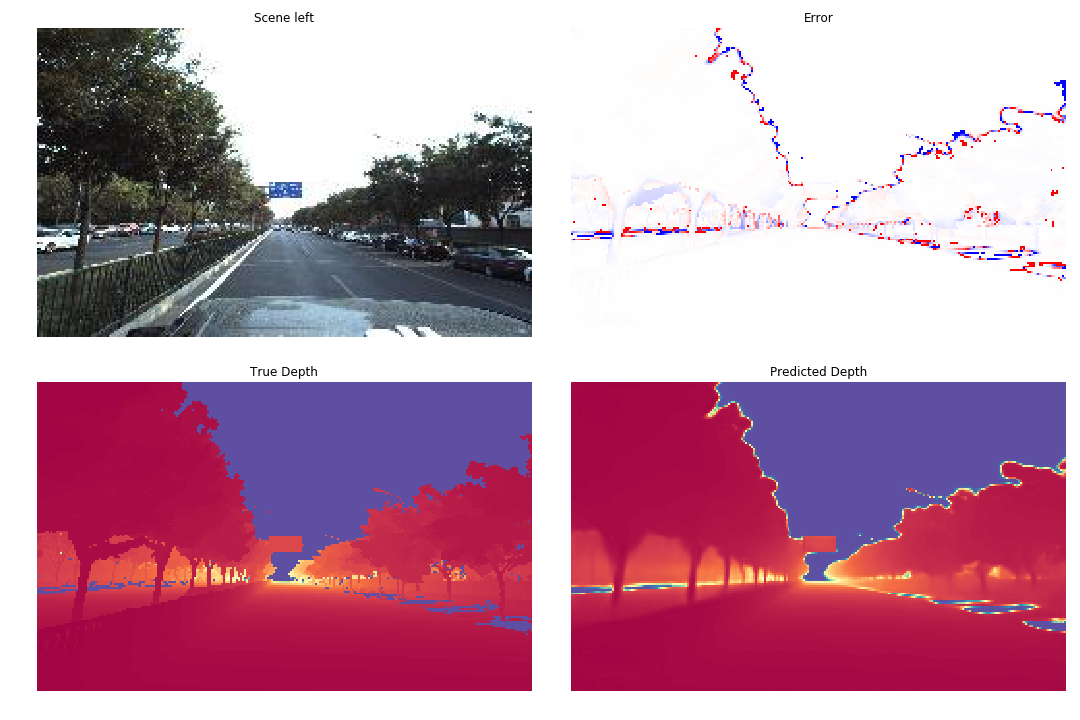
Stereo results:

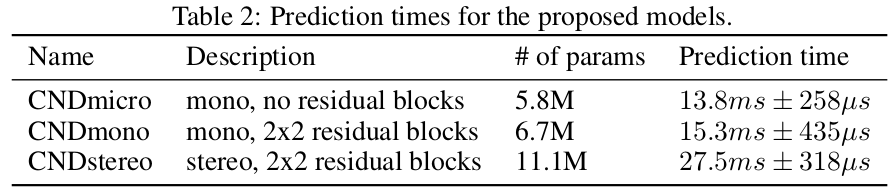
Another interesting thing about the resulting network is that it is extremely competitive in terms of speed allowing over 70 frames per second for the simplest version and 35 for the best.
One thing that kept bugging me was that the ground truth data contains several areas with missing values as can be seen in the images above. The network seems to understand that they usually happen in mirroring or very dark areas of the image and tries to learn them because otherwise they obviously result in a very large error. Masking all areas with these missing values that of course correspond to the value of an infinite distance in the dataset is not an option since that would mask the sky as a whole too which would result in terrible results (I was stupid enough to try).

In the week before the NeurIPS 2018 deadline I tried to quickly write a paper about this work in hopes to get it in but of course it was not accepted. If you are interested you can download the full paper as a PDF here.
If you like it you can also cite it of course!😉
@misc{pisoni2018cnd,
title={Efficient Convolutional Neural Networks for Depth Estimation using
Atrous Spatial Pyramid Pooling and Residual Decoder Modules},
author={Raphael Pisoni},
year={2018},
note={\url{https://rpisoni.dev/CND.pdf}},
}